Eight Ways You've Misconfigured Your A/B Test

You've read about the virtues of A/B testing feature releases. You love iterating quickly, testing quickly, and continually learning in a data-driven fashion. You appreciate the importance of keeping an eye on the statistics behind your testing, and perhaps you even use a tool or two to make sure your results are statistically valid.
But, you ran a test last week, the results have been coming in for some time now, but, the data just doesn't look quite right.
Where to begin?
Read on, eight common problems, maybe one of which might just be your problem.
Problem: You've changed your weights mid-experiment
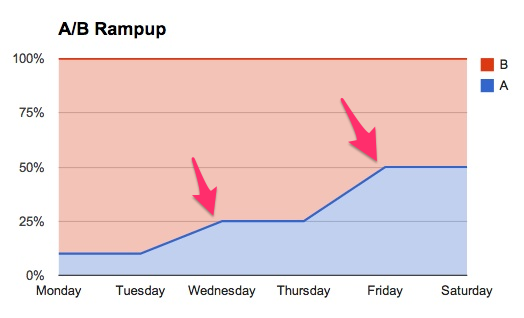
A basic premise behind A/B testing is that of running two different variants at the same time. Your bounce rates, conversion rates, and pretty much all your metrics vary from day to day, and oftentimes this variation is larger than the difference between each of your experiment variants. Running your A variant on Sunday, Monday, and Tuesday, and then switching things to B on Wednesday, Thursday, and Friday just doesn't work. An A/B test allows you to randomly assign users into one of two bins, running two variants simultaneously throughout the entire time period.
And as it turns out, switching variant weights mid-test suffers from the same problems as running variants serially. Intuitively speaking, switching from a 100/0 test (with A at 100% and B at 0%) on Tuesday to a 0/100 test on Wednesday is quite similar switching from a 99/1 test on Tuesday to a 1/99 test on Wednesday. In both cases, while the "average test" turns out to be 50/50, the results are still dominated by the day over day variation from Tuesday to Wednesday: A's metrics will be more reflective of Tuesday's metrics, and B's metrics will reflect Wednesday's metrics. If Tuesday happens to be stronger than Wednesday, then A will appear to have won; conversely, if Wednesday is stronger, then B would falsely appear to be the winner.
Although less magnified, switching from a 99/1 test to a 95/5 suffers from this problem as well.
So, make sure to measure results only over period in which your A/B ratios remain constant. And as a corollary, make sure you're also recording your A/B ratios as you change them.
Google Analytics (as well as others) use so-called "bandit tests" in which the variants ramp-up (or ramp-down) depending on variant performance. The statistics are somewhat different from standard A/B testing, and changing weights mid-experiment is of course central to how bandit testing works. As an aside, I think Google's bandit test optimizer is a nice tool for quick and dirty experiments, but I'm generally not a huge fan of bandit testing (see Dan's rant for a good reflection of my take).
Problem: Your experiment retains users
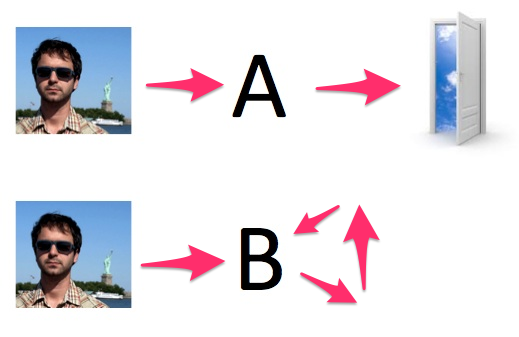
You just launched an experiment showing big improvements to your registration funnel, and registrations have increased by 10% in your experiment bucket (bucket B). But since registered users are more likely to come back to your site than non-registered users, you start seeing your B bucket growing in size. Most A/B systems bucket based on users and not visits. So what started as a 50/50 test will change to a 49/51 test on day two, and then a 48/52 test on day three, etc. as more users convert in your B group than the A. Your buckets are no longer evenly distributed either as B is biased towards logged-in and registered users.
Since your B variant is growing in size, and since this growth is coming from existing users and not new users, you'll also start to see registration rates decrease for your test group (even though it's actually outperforming the control!).
The first red flag to look out for here is your bucket sizes; even though you've configured your test to be 50/50, ratios start changing slowly over time. Once you notice this, you can try to restrict your analysis to the first few days (or week) of the experiment. Or you could also make an educated decision about the winner based on an understanding of the dynamics of what you've changed.
Bucketing based on visits instead of users is tempting, but can also add to user confusion as people will likely see multiple variants.
A related case that deserves special attention are features that are explicitly designed to create return visits to your site. For example, eBay's saved search reminders or something even as simple as an email signup form. These sorts of features will quickly create imbalances in your visit counts.
Problem: Your segmentation is wrong
When you start segmenting users in your A/B tests, you're effectively introducing a third variant for your experiment: A, B, and not in a variant. Consider the two following code snippets:
# INCORRECT
bucket = ab_selector.assign_bucket_and_log(test, user)
if (user.gender == ‘female’):
if (bucket == ‘control’):
# Render control variant
elif (bucket == ‘test’):
# Render test variant
else:
# Render control variant
# CORRECT
if (user.gender == ‘female’):
bucket = ab_selector.assign_bucket_and_log(test, user)
if (bucket == ‘control’):
# Render control variant
elif (bucket == ‘test’):
# Render test variant
else:
# Render control variant
In the first snippet, the bucketing logic appears outside the conditional. So when the call to assign_bucket_and_log is made, each and every user is logged into either the control or the test, regardless of whether or not they've met the selection criteria.
Let's take a deeper look into how this sort of experiment should be bucketing users in the correct version of the code above:
| In Segment | Not In Segment | |
| Control (A) | A | no variant |
| Test (B) | B | no variant |
Let's look at the problem with the incorrect configuration where all users are bucketed:
| In Segment | Not In Segment | |
| Control (A) | A | A |
| Test (B) | B | A |
Here, all Not In Segment users are all shown variant A, even though users within this group who were logged as seeing B ended up actually seeing A.
Problem: You're cherry picking
Say you have a new recommendation algorithm that you think people will love, but it only works for users who have previously purchased 10 items.
Consider the following incorrect snippet:
# INCORRECT
if (new_hot_algorithm.has_results):
bucket = ab_selector.assign_bucket_and_log(test, user)
if (bucket == ‘test’):
# Render test
elif (bucket == 'control'):
# Render control
else:
# Render control
You may notice that this snippet is quite similar to the segmentation snippet. In fact, the correct version of the segmentation snippet actually looks quite similar to the incorrect version of the so-called "cherry picking" experiment.
Here, the feature only works for a certain segment of users (or conditions, etc). Let's assume this experiment is deployed on your site's homepage, and that it only "works" for 10% of users. And by "works", we mean that new_hot_algorithm.has_results is true 10% of the time. And let's further assume that the experiment has been incorrectly configured as shown above, and that the experimental results showed a 5% increase in purchase conversion rates.
The problem here is with the statement: "My experiment just increased homepage conversion rates by 5%". Of course, the correct statement requires backing this out over your 10% coverage which yields increased homepage conversion rates of only 0.5%.
One could argue that this case isn't a mistake, per se. However, a fundamental goal of A/B testing is to understand the impact of your changes at hand, and oftentimes this sort of "cherry picking" can lead to confused results.
Problem: You're letting users "sneak preview" things
Say you've turned on the experiment for your new_hot_algorithm above to 5%. People start noticing, Twitter starts blowing up and users start begging you for access.
Responding to these concerns, you quickly modify your experiment to look like this:
bucket = ab_selector.assign_bucket_and_log(test, user)
if (current_url.params['sneakpreview'] == 'on'):
bucket = 'test' # INCORRECT!
if (new_hot_algorithm.has_results):
if (bucket == ‘test’):
# Render test
elif (bucket == 'control'):
# Render control
else:
# Render control
And you give your users a sneak preview link that looks something like http://www.funpalace.com?sneakpreview=on. And they tell their friends and tweet the link. And their friends' friends retweet it. And suddenly lots and lots of people are sneak previewing.
The problem with the implementation above is that your framework logs the variant on line 1, but then re-assigns the bucket (and consequently, what the user sees) on the next line. And here's what's going on:
| sneak_preview not in url | sneak_preview in url | |
| Control (A) | A | B |
| Test (B) | B | B |
The problem lies in the case where the A/B selection framework is selecting and logging variant A, but the sneak_preview override forces the user to see variant B.
Problem: Caching!
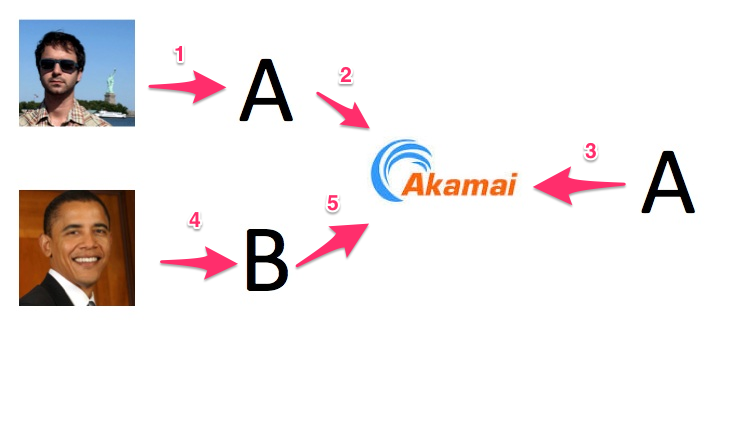
Caching is generally at odds with A/B testing. Say your homepage is entirely static, and that you use Akamai (or some other edge network) to cache your homepage. And say one day you decide to run a test to change the copy on the homepage.
Your code looks something like this:
bucket = ab_selector.assign_bucket_and_log(test, user) if (bucket == ‘control’): greeting = "Greetings!" elif (bucket == ‘test’): greeting = "Welcome!"
And every 30 minutes (or however long your caching TTL is), exactly one request will fall through your edge network to your data center (steps 1 and 2 in the picture above), exercise the code above (step 3 in the picture), which will in turn choose exactly one of the two variants. All subsequent requests for your homepage (such as steps 4 & 5) will return the cached version of the page, each of which say either "Greetings!" or "Welcome!".
There are plenty of other ways that caching can invalidate your A/B testing results. So think about how you're using memcache, squid, edge networks, and any other source of caching at any layer.
Problem: You're using separate bucket logic for both logged in and logged out users

Perhaps the most technical of the seven errors, this one makes some deeper assumptions about how your bucketing works. Many A/B frameworks bucket by taking a hash of either user ids or session identifiers. The advantage is that a user's bucket can be assigned randomly, but no explicit storage (i.e. a database) is required to maintain state. For more details, see Section 4.1.1 on Kohavi et al's KDD paper, or refer to Etsy's implementation on GitHub.
While hashing schemes are great, they break down if you use different bucketing keys for your logged out vs logged in users.
Let's consider an example visit where a user arrives, sees a test, and then logs in:
| User arrives at homepage | No Variant |
| User searches, triggers test | A |
| User logs in | No Variant |
| User searches, triggers test | B |
Since the user's unique identifier changes after she logs in, it's possible that her A/B bucket will change as well. For example, if Jane's session identifier is the string "QsfdET34" which hashes to bucket A, after she logs in, her email (jane@gmail.com) could very well hash to bucket B.
Let's assume that your A/B analytics discards visits like Jane's that have conflicting A and B variants. And say you're running a 90/10 experiment:
P(logged out & A) = 90% P(logged out & B) = 10% P(logged in & A) = 90% P(logged in & B) = 10%
Now let's look at visits that are both logged in and logged out:
P(logged in & A, logged out & A) = 81% P(logged in & B, logged out & B) = 1% P(logged in & A, logged out & B) = 9% P(logged in & B, logged out & A) = 9%
Your analytics will discard the last two as inconsistent visits, leaving a break down of 81% and 1% for your A vs B variants. But your experiment was configured as a 90% A and 10% B, resulting in incorrectly sized bins.
The simplest solution here is to bucket on only logged in users or only logged out users, but not both.
Problem: You actually have no idea how your A/B system works

There's more complexity in A/B testing than appears at first glance, and understanding basic measurement constructs is critical in spotting problems.
Understanding your tools is critical to running a valid A/B test. You may be using a complete end-to-end A/B tool like Google Analytics Content Experiments. Or perhaps you're using Optimizely's slick JavaScript A/B framework and measuring results with Mixpanel. Maybe you're doing A/B selection yourself and even using your own pipeline for analysis.
Almost two years ago, Google made some fundamental changes to how they sessionize their web visits. One side effect of this change involved how they count visits from third party referring sites (including email, social media, etc.); understanding this change is critical not just for A/B testing email, but for generally understanding email analytics. And of course the example above illustrates some unexpected side effects of hash-based bucketing.
A/B testing is a great way of measuring the effectiveness of the products and improvements you're building. A well designed A/B system should make releasing an experiment alongside a feature release just as easy as releasing the feature by itself. But unlike most software debugging where errors can be easily reproduced by refreshing a web page or running a script, such is not the case with analytics and certainly not with A/B testing. So even if your A/B framework makes it really easy to setup and run A/B tests, A/B testing can get very complicated very quickly, and it isn't always easy to debug things when they go wrong.
Thanks to Dan McKinley for reading drafts of this.